Abstract
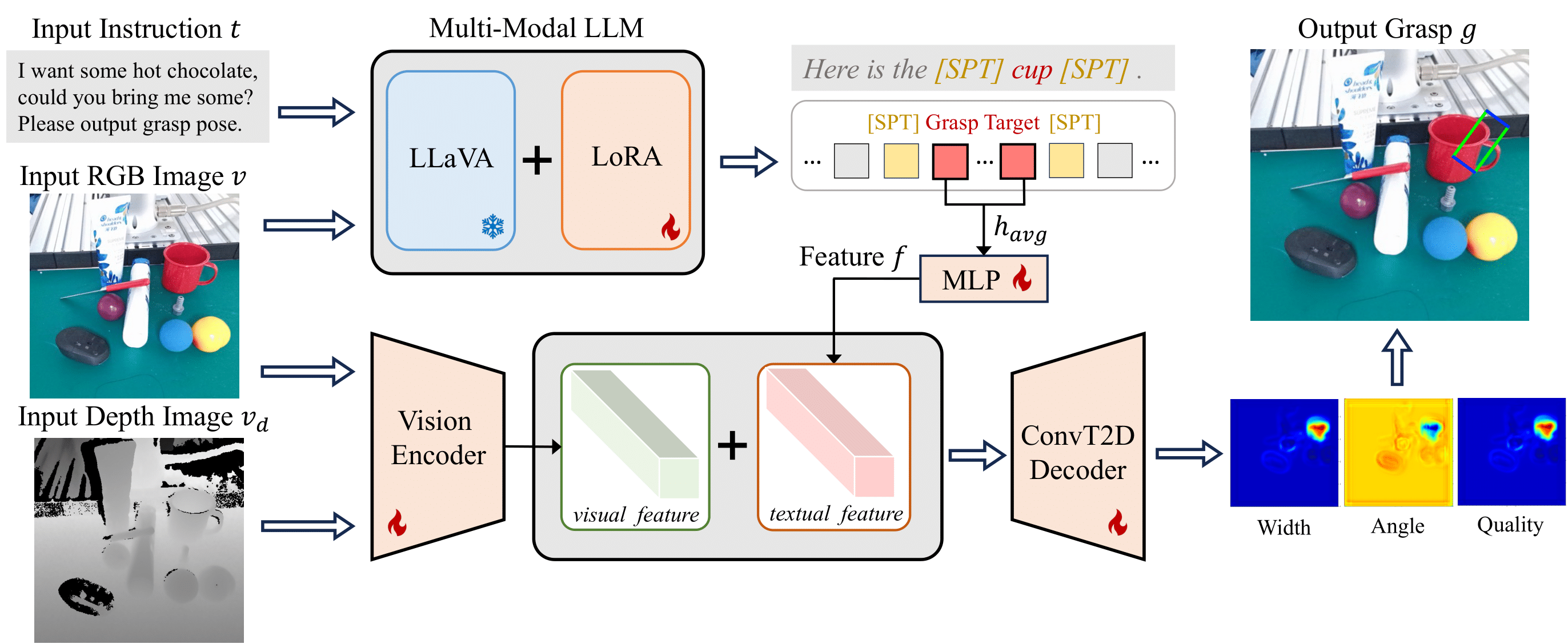
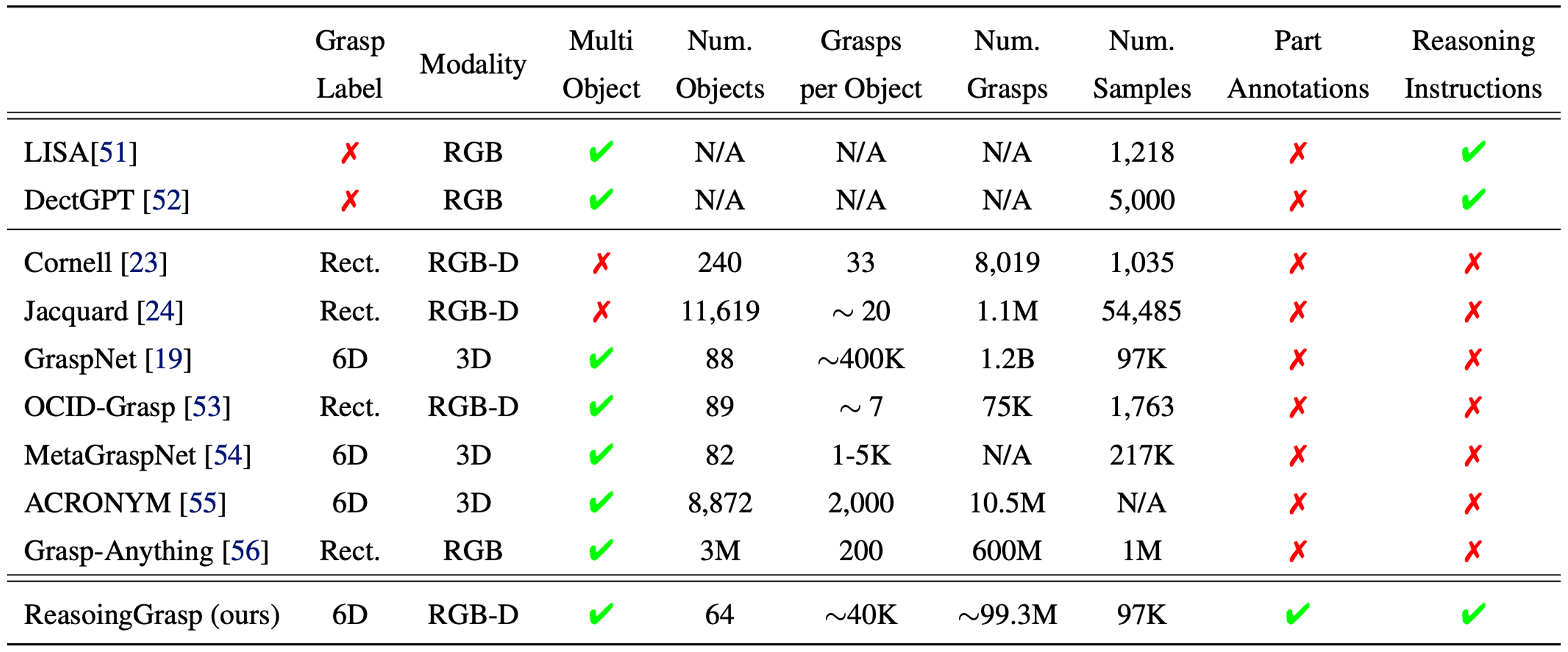
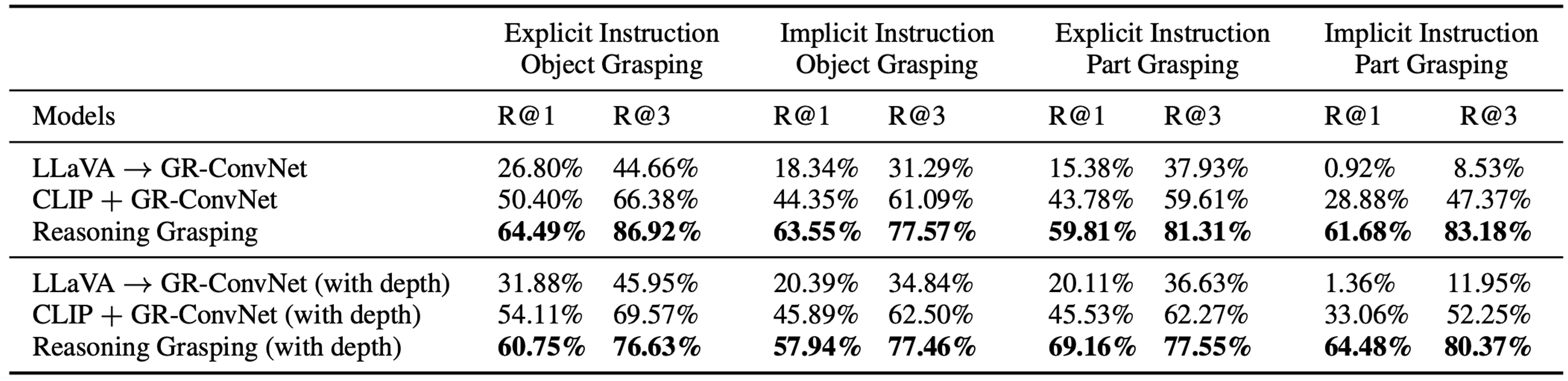
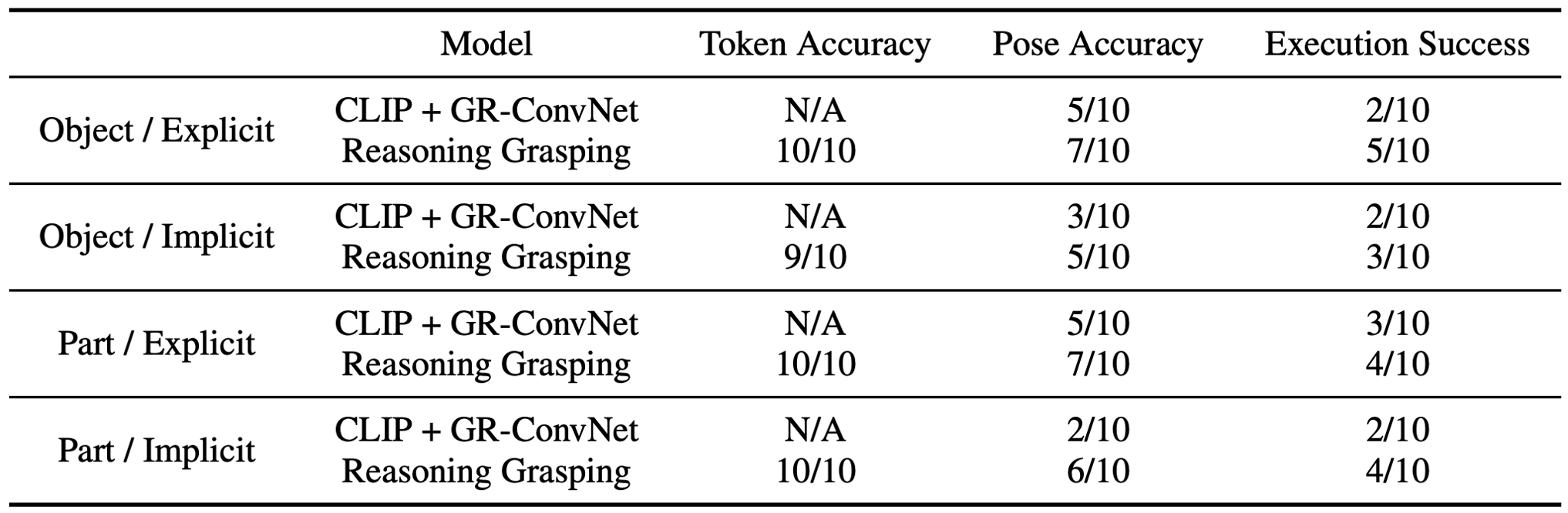
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multimodal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Motivations and Application Scenarios
Motivations
Advance robotic systems should not only understand direct human commands but to also possess the reasoning capability to interpret implicit instructions. These implicit instructions can provide a general description of users’ needs, requiring the robot to infer the grasping target on its own, without explicitly naming the object.
Application Scenarios
1. Users cannot visually confirm the robot’s surroundings: For example, blind people can
instruct the robot to “find a sweater in a warm color that matches the pants”. The robot could
also be asked to “find something to hold these papers together”, where it might choose from
a stapler, paper clips, or binder clips based on availability.
2. Tasks that require internal knowledge for decision making: Robots can utilize their internal
knowledge for tasks like sorting in recycling facilities. They could be instructed to “sort
materials that are recyclable and compostable”, identifying items based on texture and
material type, which facilitates sorting without the need to know whether the objects are
recyclable or not.
3. Naming objects is impractical or complex: In some situations, explicitly naming objects is
impractical or the names are complex and difficult to remember. For instance, telling a robot, “I
need my morning medicine”, allows the robot to use its routine knowledge to fetch the correct
medication without the user needing to recall specific drug names, which are usually long and
complex.
4. Managing multiple items: Explicitly naming multiple objects can be cumbersome and
inefficient. In emergency medical situations, a medical robot might be instructed to “gather all
items necessary for suturing wounds”. It would need to discern which tools and supplies are
relevant, such as needles, thread, and antiseptics, based on the medical context provided. For
general tidying tasks in home organization, a home robot could be instructed with phrases like
“The living room is messy, tidy up by picking up toys”, allowing the robot to identify and collect
toys without naming each item individually (e.g., teddy bear, toy train, etc.).